Data Processing with nltk
The Python package, NLTK, is a great starter kit for anyone wanting to learn natural language processing. It can easily perform functions in any text such as finding parts of speech, tagging entities of any kind (person, place, company, etc.), figure out the stem of a word, and so much more. In this project, I’ll focus on finding and tagging people, places, and/or corporations, also known as Named Entity Recognition (NER). NER problems can be broken down into two parts: detecting entities and classifying them into the kind of entity that they are (person, place, title, etc.). Another helpful way to think about this is that after identifying the parts of speech of every word, you’re detecting and classifying the proper nouns. Is this proper noun associated with a person, place, company, etc.?
In this project, we’ve used Stanford’s CoreNLP API through the Python package NLTK. The initial steps are a little unconventional. Before beginning on any kind of parsing or tagging, the CoreNLP server must be started first by a Java command. The purpose of this server is to ensure that it can be interfaced through other languages besides Java (in this case, Python). Although it is possible to run the server through Python, the performance is a lot faster through Java. Afterward, the parser tags names in the specified text. An additional benefit to running the server is that you can also visit the host URL (http://localhost:9000) and experiment the text with any annotator in the server sit. This is a great debugging tool for seeing how the NER tagger identifies and classifies certain entities. Here’s the code for NER tagging.
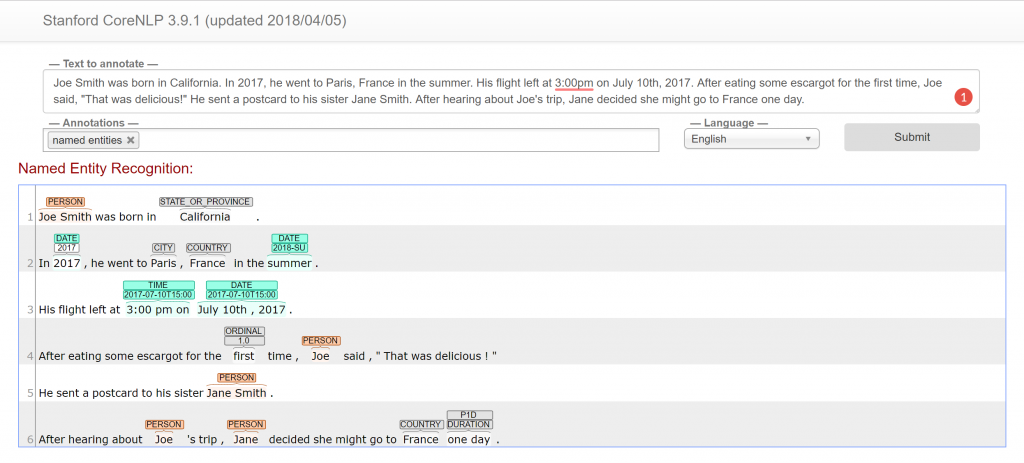
This is the server site for the CoreNLP server. Check out the live version at http://corenlp.run/
With the NER tagger given, we have found a few interesting cases on how it find people’s names in documents written in contemporary English. Firstly, it can detect first name abbreviations and count that as a name. Although the tagger was able to pair “Wm.” to the following last name, it sometimes did not pair on other abbreviations such as Thos. or Benj. This is not surprising since Thos. and Benj. are not common throughout the entire CCP dataset, since there are around 6 instances of those abbreviations in a set of over 5000 names. Another example is when a location is mislabelled as a person, such as the city of Carlisle in Pennsylvania. In the future, we could take these instances, label them, and feed them into the tagger for training to tweak the NER tagger.
When gathering names from the NER tagger, we’ve noticed that we have collected a lot of first and last names separately. NER taggers can sometimes detect only one piece of a name (first or last). To reduce repeating these pieces, we need to “link” them to their original full names. For example, in some documents, the name Jas. Harris is often interpreted as two different names due to the abbreviation. A simple hash table/map-like structure would work. This is helpful so that when we detect and store these names from a corpus ten times larger than our current one, collecting names would be much faster given that the insertion and update operations are quick (O(1) time).
Tune in for the next post soon! Also, what are your thoughts and suggestions on this so far? Comment down below!